
GEPC: Making AI Decisions Understandable Through Part-Based Explanations
Published in Oregon State University, 2024
How can we trust AI systems when we can’t understand their decisions? This research presents a breakthrough method that transforms opaque neural network predictions into human-readable explanations—without requiring massive annotation efforts.
The Black Box Problem
Deep learning models power everything from medical diagnoses to self-driving cars. They achieve remarkable accuracy, but there’s a fundamental problem: we don’t know why they make the decisions they do.
When an AI diagnoses a medical condition, approves a loan, or identifies objects in safety-critical systems, stakeholders need more than just a prediction—they need to understand the reasoning behind it. The stakes are too high for blind trust.
Current explanation methods face a critical dilemma:
- Local explanations show what matters in a single image but offer no broader insights
- Concept-based approaches require annotating thousands of images with detailed labels—a prohibitively expensive and time-consuming process
- Saliency maps highlight regions but lack semantic meaning that humans can actually understand
What if you could achieve global interpretability with minimal annotation effort?
Our Solution: GEPC
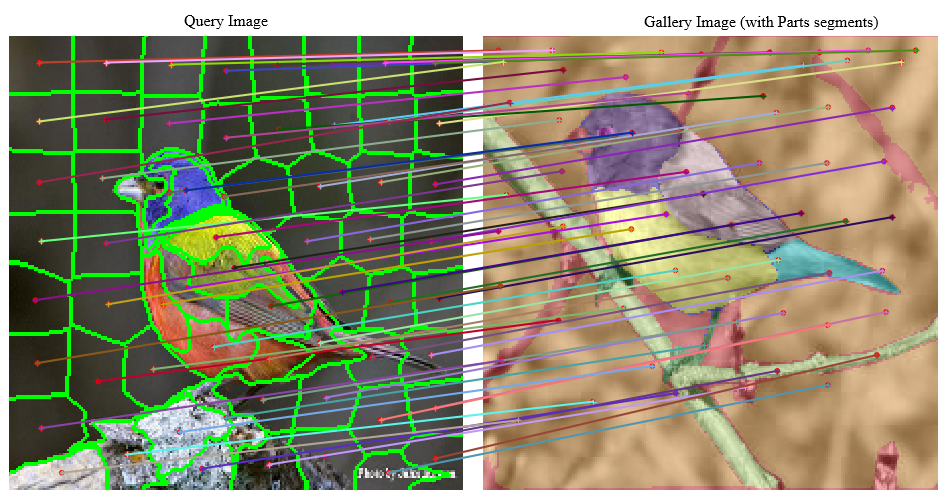
Global Explanations via Part Correspondence (GEPC) bridges this gap with an elegant insight: we can transfer part labels from a small set of annotated images to an entire dataset by leveraging what the neural network has already learned.
The key innovation: Neural networks naturally learn high-level concepts like object parts during training. GEPC exploits this by:
- Minimal annotation: Label parts in just 15% of images
- Intelligent transfer: Match these labels to similar images using the model’s own learned features
- Global synthesis: Aggregate local explanations into comprehensive, human-readable rules
The result: Instead of saying “these pixels matter,” GEPC produces explanations like: “This model identifies Bee-Eaters primarily by detecting {bird-head, bird-wing, bird-beak} together” or “Sports cars are recognized when the model finds {car-body above wheels, windshield adjacent to hood}.”
Why This Matters
Trust Through Transparency
In high-stakes domains, understanding AI reasoning is not optional—it’s essential:
- Healthcare: Doctors need to know if a diagnostic AI is focusing on relevant anatomical features or spurious patterns
- Autonomous vehicles: Safety requires knowing whether the system identifies pedestrians by meaningful features or artifacts
- Legal and financial systems: Fairness demands transparent decision-making processes
GEPC provides this transparency at scale, making AI systems accountable and auditable.
Practical Efficiency
Traditional concept-based explanation methods require extensive human annotation—often thousands of carefully labeled images per category. This creates a massive bottleneck:
- Annotation is expensive and time-consuming
- Expert knowledge is required for specialized domains
- The process doesn’t scale to large datasets or many classes
GEPC changes the economics: By transferring labels from just 15% of images, the approach reduces annotation effort by 85% while maintaining high-quality explanations. This makes interpretability practical for real-world applications.
Debugging and Validation
Global explanations reveal when models learn the wrong patterns:
- Is your bird classifier actually using background features instead of the bird itself?
- Does your medical AI rely on spurious correlations in the training data?
- Are critical features being ignored?
GEPC provides the diagnostic tools to answer these questions, enabling developers to identify and fix problematic model behaviors before deployment.
What Makes GEPC Different
Leveraging learned representations: Unlike methods that require training new explanation models, GEPC uses the features the classifier has already learned—making it truly post-hoc and model-agnostic.
Part-based semantics: Explanations in terms of object parts (heads, wings, wheels) are naturally interpretable to humans, unlike abstract concepts or pixel-level importance maps.
Global coverage: While local explanations vary image-by-image, GEPC synthesizes them into decision rules that describe the model’s behavior across the entire dataset—revealing systematic patterns in how the AI makes decisions.
Relationship awareness: Beyond identifying parts, GEPC captures spatial relationships (“head above body,” “windshield adjacent to hood”), providing richer explanations that match human reasoning.
Key Achievements
Our validation across multiple datasets demonstrates GEPC’s effectiveness:
- 84.28% average accuracy in transferring part labels across 158 ImageNet categories
- Successful deployment on Stanford Cars (196 classes), CUB-200 Birds (200 species), and ImageNet
- Effective coverage: Global explanations covering 70-95% of test images with concise decision rules
- Model-agnostic: Works across different architectures (ResNet, DenseNet, VGG19)
The method achieves interpretability that’s both comprehensive and practical—explaining model behavior with just a handful of human-readable rules per class.
From Research to Real Impact
The implications extend far beyond academic interest:
Medical AI: Radiologists using AI diagnostic tools can verify that the system focuses on clinically relevant features, not imaging artifacts or metadata.
Autonomous systems: Engineers can validate that perception systems identify objects based on meaningful visual features, ensuring robustness across different conditions.
Fairness and compliance: Organizations deploying AI can demonstrate that models make decisions based on legitimate features rather than protected attributes or biases.
Educational applications: Teachers and students can understand how modern AI actually works, demystifying machine learning through concrete, visual examples.
The Bigger Picture
As AI systems become more capable and more widely deployed, the interpretability gap grows more dangerous. We’re deploying sophisticated models in critical domains while treating them as black boxes—a fundamentally unsustainable approach.
GEPC represents a path forward: practical, scalable interpretability that works with existing models and datasets. By making AI decisions understandable, we enable:
- Better debugging of model failures
- Increased trust from users and stakeholders
- Improved safety through transparent validation
- Fairer outcomes by exposing biased patterns
This isn’t just about explaining individual predictions—it’s about fundamentally changing how we develop, deploy, and trust AI systems.
Read the Full Paper
Conference Paper: Rathore, K. and Tadepalli, P. “Generating Part-Based Global Explanations Via Correspondence”
What You’ll Find in the Paper
- Complete GEPC framework combining correspondence and explanation synthesis
- Validation across three major datasets (Stanford Cars, CUB-200, ImageNet)
- Comparison with alternative explanation methods
- Analysis of both part-based and relational explanations
- Practical guidance for applying GEPC to new domains
The Method at a Glance
Step 1: Annotate parts in 15% of images per class
Step 2: Find visually similar images using gradient-weighted features
Step 3: Transfer part labels via Hyperpixel Flow correspondence
Step 4: Generate minimal sufficient explanations (MSXs) for each image
Step 5: Synthesize global rules using greedy set cover
The entire pipeline works with pre-trained models—no retraining required.
Beyond Computer Vision
While demonstrated on image classification, the GEPC approach generalizes to other domains where:
- Models learn hierarchical representations
- Parts or components have semantic meaning
- Global understanding is needed for trust and validation
Future applications could include:
- Gene expression analysis in computational biology
- Activity recognition in video understanding
- Document understanding and question answering
- Audio and speech processing
The fundamental insight—leveraging learned representations to efficiently transfer semantic labels—applies wherever deep learning faces interpretability challenges.
Contact & Collaboration
Interested in applying GEPC to your domain or collaborating on interpretable AI research?
| Kunal Rathore | rathorek@oregonstate.edu |
| Prasad Tadepalli | tadepall@oregonstate.edu |
Oregon State University, Corvallis, OR
This research advances the frontier of explainable AI, making sophisticated models understandable, trustworthy, and safer for real-world deployment.